
인덱스(Index) 알아보기

인덱스(Index)란?
인덱스는 쉽게 말해 책의 목차와 같다.
매우 매우 두꺼운 책에 목차 페이지가 없다면 어떨까요?
책 안에 내용을 찾을 때 여러분은 어디를 살펴보시나요?
우리들은 항상 무언가를 찾을 때 주소, 목차를 보고 찾습니다.
DB Index도 똑같습니다.
데이터베이스는 많은 데이터를 관리해주는 매우 중요한 기술입니다.
그런 많은 데이터 안에서 찾고 싶은 내용을 어떻게 찾을까요?
그것을 도와주는 것이 바로 DB Index 입니다.
인덱스 종류
인덱스 종류론 크게 클러스터드 인덱스와 넌클러스터드 인덱스로 나눌 수 있습니다.
클러스터드 인덱스
- 테이블당 1개씩만 허용
- PK설정시 그 컬럼으로 클러스터드 인덱스가 생성됨
- 책으로 비유하면 페이지 숫자를 알고 있고 바로 찾을 수 있음
넌클러스터 인덱스
- 테이블당 여러개 허용
- 클러스터 인덱스보다 검색 속도는 더 느리지만 데이터의 입력,수정,삭제는 더 빠름
- 인덱스 페이지를 한번 거쳐서 데이터 접근
- 책으로 비유하면 페이지 숫자를 몰라 목차를 찾아가 숫자를 찾은 후 이동함
DB가 데이터를 읽어오는 방법
데이터베이스는 데이터를 읽어올 때 크게 2가지 방법으로 읽어옵니다.
시퀀셜 엑세스
물리적으로 인접한 페이지를 차례대로 읽는 방식, 그렇기에 인접한 페이지를 여러개 읽을 수 있음
- 테이블 풀스캔이 시퀀셜 엑세스를 사용함
- Multi Block I/O 방식으로 효율적이게 디스크를 읽어옴
랜덤 엑세스
정해진 순서없이 이동하는 만큼 디스크의 물리적인 움직임이 필요하고, 다중 페이지 읽기가 불가능함
- Index range scan이 랜덤 엑세스를 사용함
- Single Block I/O 방식으로 레코드 하나를 읽기 위해 매번 I/O가 발생함
- 읽을 데이터가 일정량을 넘게되면 인덱스 스캔보다 풀스캔이 유리함
- 인덱스는 큰 테이블에서 소량의 데이터를 검색할 때 유리
- 랜덤 I/O를 어떻게 줄이는지가 중요
- 스캔 범위를 줄여야함
인덱스의 탐색 과정
인덱스는 수직적 탐색과 수평적 탐색으로 나눌 수 있습니다.
수직적 탐색
시작과 끝지점을 찾는 것 학생 명부 탐색
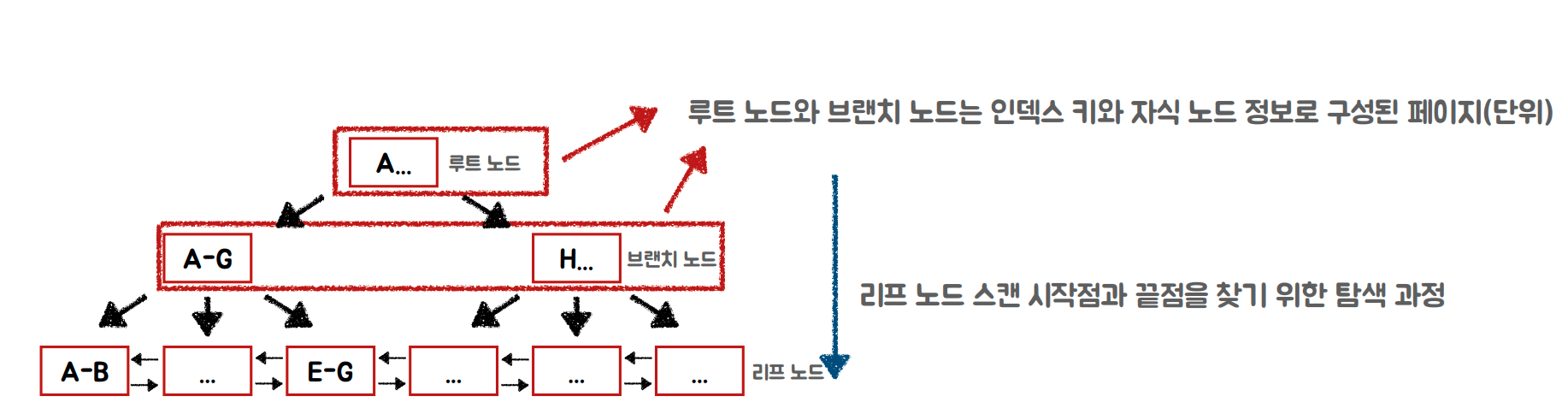
수평적 탐색
최종 데이터를 찾는 것 직접 교실 찾아가기
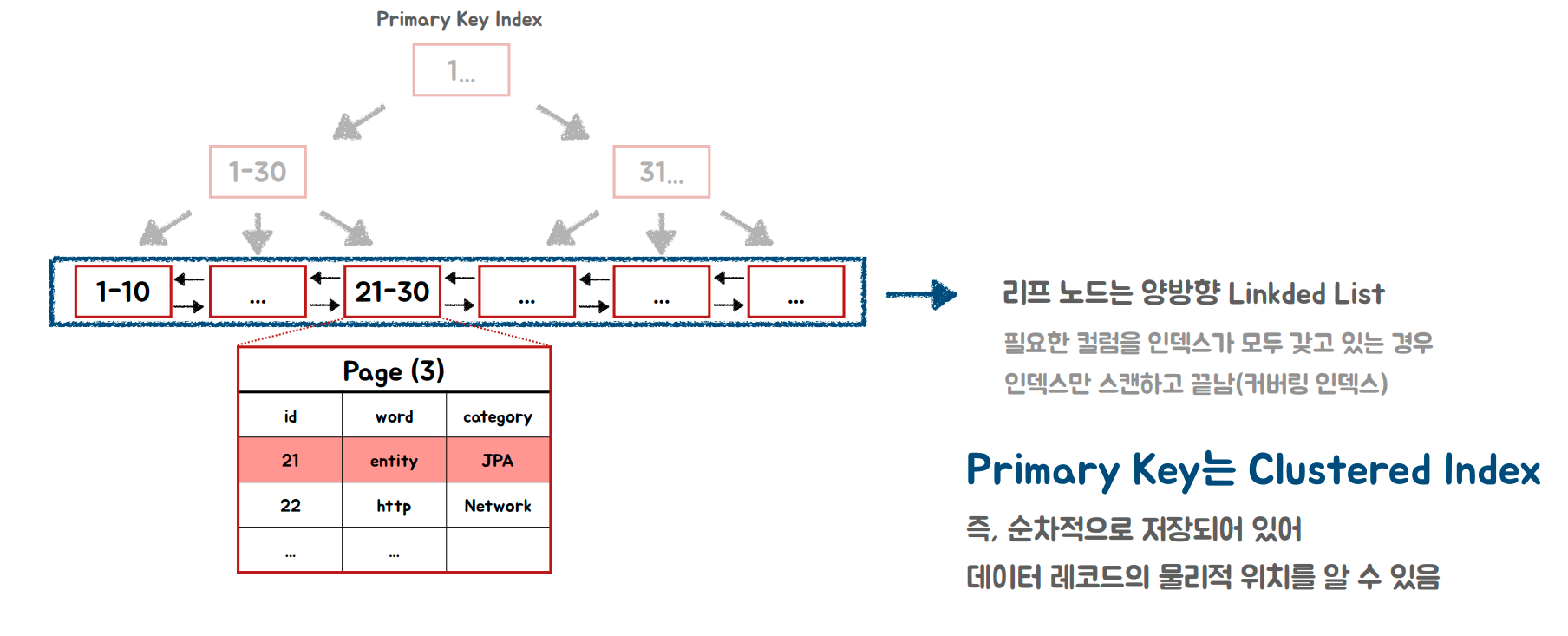
- 수평적 탐색 중 넌클러스터드 인덱스라면 랜덤 액세스, 즉 싱글 I/O가 발생함
- 클러스터드 인덱스인 PK는 mysql기준으로 순차적으로 저장되어있기 때문에 시퀀셜 엑세스가 발생함
- 이 부분을 잘 튜닝해야 성능이 상승함
인덱스를 튜닝해보자
인덱스를 가장 쉽게 튜닝할 수 있는 방법은 mysql 워크벤치를 활용한 방법입니다.
워크벤치에서 쿼리를 작성한 후 실행계획 버튼을 눌러 이 쿼리가 어떻게 동작할 지에 대해 그림으로 표현해주는 기능을 통해 튜닝에 접근할 수 있습니다.
그리고 쿼리문 앞에 Explain 이라는 명령어를 통해 세부적인 내용도 알아볼 수 있습니다.
Explain 을 통해 나오는 세부적인 내용 중 우리가 살펴봐야 할 컬럼은 7개 입니다.
실행계획 살펴보기

- id
- SQL 문이 수행되는 순서
- 위의 예시엔 id가 모두다 1이지만 2인 경우가 있다면 1→2 순서로 실행된다고 보면 됨
- id가 같은 경우는 조인을 의미함
- select_type
- SIMPLE → 단순한 SELECT 문
- PRIMARY → 서브쿼리를 감싸는 외부 쿼리, UNION이 포함될 경우 첫번째 SELECT 문
- SUBQUERY → 독립적으로 수행되는 서브 쿼리 (SELECT, WHERE 절에 추가된 서브쿼리)
- DERIVED → FROM 절에 작성된 서브쿼리
- UNION → UNION, UNION ALL로 합쳐진 SELECT
- DEPENDENT SUBQUERY → 서브쿼리가 바깥쪽 SELECT 쿼리에 정의된 컬럼을 사용

- DEPENDENT UNION → 외부에 정의된 컬럼을 UNION으로 결합된 쿼리에서 사용
DEPENDENT 타입은 대부분 튜닝해야함 (성능저하)
- type
- ALL → 테이블 풀스캔
- range → 인덱스 레인지 스캔
- index → 인덱스 풀스캔
- eq_ref → 조인이 수행될 때 드리븐 테이블의 데이터에 PK 혹은 고유 인덱스로 단 1건의 데이터를 조회할 때
- ref → eq_ref와 같으나 데이터가 2건 이상일 경우
- const → 조회되는 데이터가 단 1건 일 때
- system → 테이블에 데이터가 없거나 한 개만 있는 경우
- key
- 옵티마이저가 실제로 선택한 인덱스
- rows
- SQL문을 수행하기 위해 접근하는 데이터의 모든 행 수
- filtered
- 필터링 되고 남은 레코드 비율
- 스토리지 엔진이 읽어들인 데이터 중 MySQL 엔진이 필터링하고 남은 비율을 의미
- 즉, 높을 수록 디스크를 효율적으로 탐색했다는 의미
- extra
- Distinct → 중복 제거시
- Using where → WHERE 절로 필터시
- Using temporary → 데이터의 중간 결과를 저장하고자 임시 테이블을 생성, 보통 DISTINCT, GROUP BY, ORDER BY 구문이 포함된 경우 임시테이블을 생성
- Using index → 물리적인 데이터 파일을 읽지 않고 인덱스만 읽어서 처리, 커버링 인덱스라고 함
- Using filesort → 정렬시
그래서 어떻게 하는게 좋은 튜닝인가요?
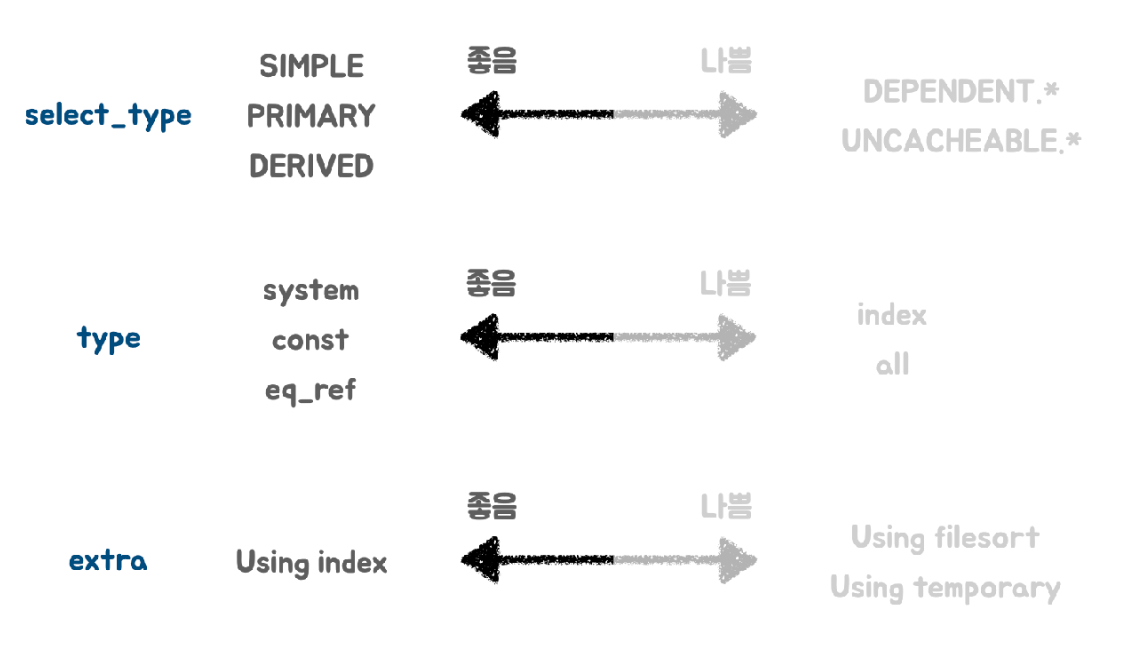
위 사진의 select_type, type, extra 3부분만 신경써서 튜닝해도 꽤나 좋은 성능을 낼 수 있을 것입니다.
정리
간단하게 인덱스의 정의, 종류, 탐색과정, 튜닝까지 알아보았습니다.
세부적인 내용과 구현 및 실습까지 진행하기엔 분량이 너무 많을 것 같아 핵심적인 내용만 추려 정리해보았습니다.
백문이불여일타 직접 SQL을 작성하여 DB의 인덱스를 추가했다 뺏다하여 테스트해보시면 더욱더 쉽게 이해가기 때문에 꼭! 워크벤치의 실행계획을 사용해보세요!
그럼 이만 끝!
Reference
- Real MySQL
- 우아한 테크캠프 Pro - 안정적인 서비스 만들기
댓글남기기